高级排序算法 堆排序
堆排序是什么?
当我们需要对一组数据进行排序时,堆排序是一种高效的排序算法。它利用了堆这种数据结构的特性进行排序操作。
堆是一种特殊的树状数据结构,具有以下性质:
- 它是一个完全二叉树,即除了最后一层外,其他层都被完全填满,并且最后一层的节点都靠左对齐。
- 堆中每个节点的值都大于等于(或小于等于)其子节点的值,这被称为最大堆(或最小堆)性质。
堆排序算法的基本思想如下:
- 首先,将待排序的数据构建成一个最大堆(或最小堆)。
- 构建堆的过程可以使用数组来表示堆,将数组视为完全二叉树的形式。
- 接着,将堆的根节点(即数组的第一个元素)与最后一个元素交换位置,然后将堆的大小减一。
- 对交换后的堆进行调整,使其重新满足堆的性质。
- 重复步骤3和步骤4,直到堆的大小为1,此时整个数据集就已经排序完成。
堆排序的关键在于构建和调整堆的过程。构建堆的过程可以通过自底向上的方式,从最后一个非叶子节点开始,逐个向上调整每个节点,以满足堆的性质。调整堆的过程可以通过自顶向下的方式,从根节点开始,逐个向下调整每个节点,以保持堆的性质。
堆排序的时间复杂度为O(nlogn),其中n是数据集的大小。由于堆排序具有原地排序的特性,即不需要额外的存储空间来进行排序操作,因此它是一种空间复杂度较低的排序算法。
如下介绍了整个过程:
开始时:

1、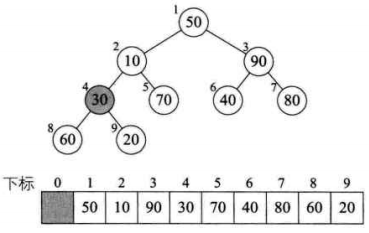
2、
3、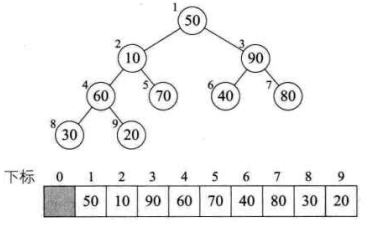
4、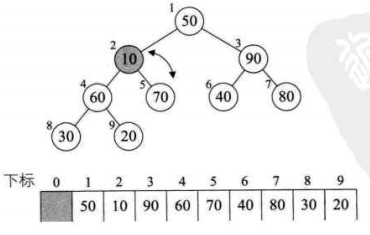
5、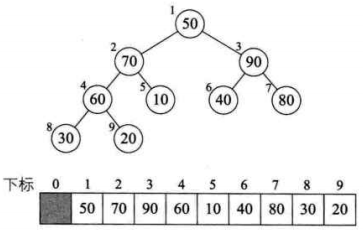
6、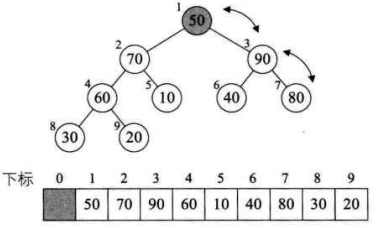
7、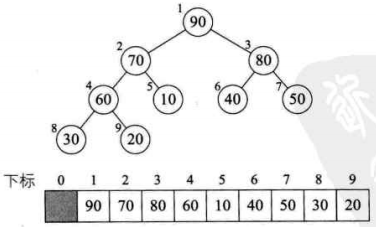
8、此时已经取得堆的最大值了(90),把它和数组的最后一位交换(20),然后这个 90 移出堆(指针向前移动一位就行了),这时就取得了最大值
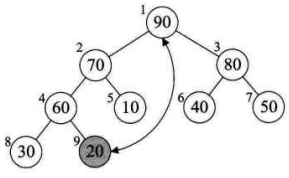
9、重复上面的步骤
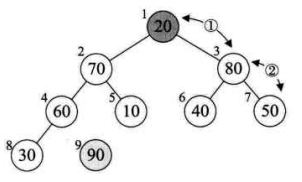
10、再次取得了最大值(80),再次将其移出数组,然后再次令他与堆的最后一位交换,此时就取得排序好的最大两位数了(80、90)
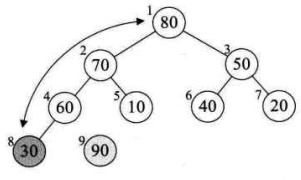
11、
12、交换取得倒数第三大的数(70)
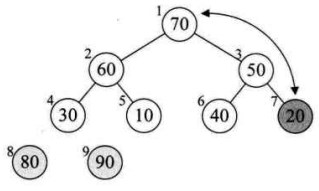
13、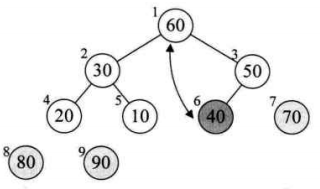
14、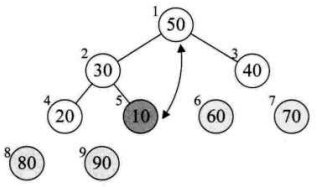
15、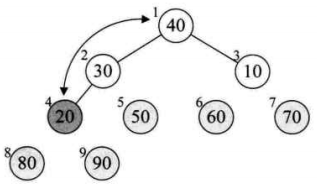
16、
17、
堆排序时间复杂度: 堆排序对原始记录的排序状态并不敏感,其在性能上要远远好过于冒泡、简单选择、直接插入排序。
堆排序的代码
补充个知识点
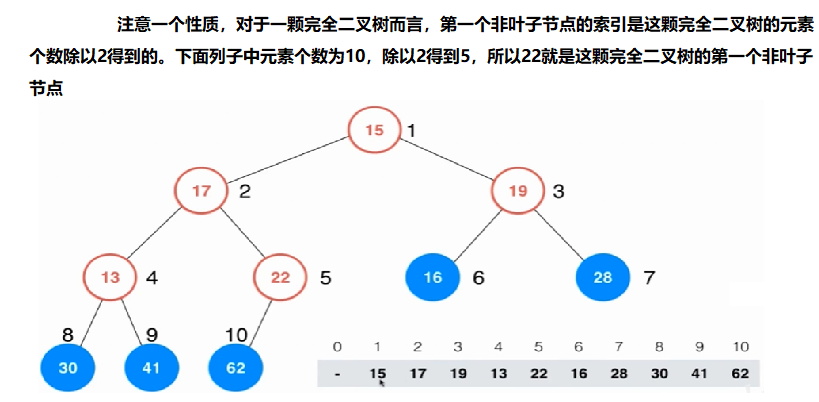
如果还是不懂这个除二是咋来的,可以看 左神的视频 1:09:00
主要就是避免一个个从头构建堆
具体的堆排序的代码:
/**
* 堆排序
*/
private static void heapSort(int[] arr) {
// 将待排序的序列构建成一个大顶堆
// 这个 arr.length / 2 可以取得完全二叉树的第一个非叶子节点的索引
for (int i = arr.length / 2; i >= 0; i--) { // O(N)
heapify(arr, i, arr.length); // O(logN)
}
// 逐步将每个最大值的根节点与末尾元素交换,并且再调整二叉树,使其成为大顶堆
for (int i = arr.length - 1; i > 0; i--) { // O(N)
swap(arr, 0, i); // 将堆顶记录和当前未经排序子序列的最后一个记录交换 // O(1)
heapify(arr, 0, i); // 交换之后,需要重新检查堆是否符合大顶堆,不符合则要调整 // O(logN)
}
}
/**
* 构建堆的过程
*
* 删除在 index 位置上的某个数
* heapSize 表示堆的大小(因为不是整个数组都是堆,数组可能没有被填满)
*/
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1; // 左孩子的下标
while (left < heapSize) { // 下方还有孩子的时候
// 比较两个孩子(左右孩子)谁的值大,把下标给 largest
int largest = left + 1 < heapSize // 先判断下标有没有越界
&& arr[left + 1] > arr[left] ? left + 1 : left;
// 父和最大的那个孩子之间,谁的值更大,把下标给 largest
largest = arr[largest] > arr[index] ? largest : index;
// 如果相等说明最大值就是这个 index 的节点,因此无需交换了
if (largest == index) break;
swap(arr, largest, index);
// 现在到下面一个节点重复操作
index = largest;
left = index * 2 + 1;
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
补充:打印数组完全二叉树的工具
为了方便下面的代码调试,这里提供一个打印数组完全二叉树的工具类
代码参考:gist 地址
[93, 97, 92, 87, 49, 54, 60, 84, 40, 7]
生成效果:
93
97 92
87 49 54 60
84 40 7
补充个生成随机数组的工具方法:
/**
* 生成随机数组
*/
public static int[] generateArray(int len, int max) {
int[] arr = new int[len];
for (int i = 0; i < arr.length; i++) {
arr[i] = (int) (Math.random() * max);
}
return arr;
}
测试堆排序
public static void main(String[] args) {
// int[] arr = new int[]{3, 9, 6, 7, 4, 3, 5, 8, 2};
int[] arr = generateArray(10, 100);
int[] arrCopy = Arrays.copyOf(arr, arr.length);
heapSort(arrCopy);
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(arrCopy));
// 上面提供的工具类
CompleteBinaryTree.TreeNode root = CompleteBinaryTree.Tool.createTree(arrCopy);
CompleteBinaryTree.Print.PrintTreeNode(root);
}
打印结果:
[0, 80, 57, 18, 48, 57, 50, 23, 19, 19]
[0, 18, 19, 19, 23, 48, 50, 57, 57, 80]
0
18 19
19 23 48 50
57 57 80
堆排序拓展题目 🔥
已知一个几乎有序的数组,几乎有序是指,如果把数组排好顺序的话,每个元素移动的距离可以不超过 k,并且 k 相对于数组来说比较小。请选择一个合适的排序算法针对这个数据进行排序。
整个过程 左神的视频 1:20:00
利用小根堆
例如:k = 6
那把数组的前 7 个数放在小根堆里面(因为距离不会超过 6),那排完序后数组的 0 位置就是最小值了,然后把 0 位置的数弹出,数组 first 和 end 下标向后移动一位,此时新加入进来的那个元素(end 下标指向的元素)执行堆化(shiftDown),再次重复操作,最后就全部有序了。
这里使用 Java 中的实现类 PriorityQueue,具体它的细节参考这篇 《Java 集合类学习 PriorityQueue》
public static void sortedArrDistanceLessK(int[] arr, int k) {
// 这里使用自带的堆工具(默认小根堆)
PriorityQueue<Integer> heap = new PriorityQueue<>();
int index = 0;
// 避免 k 比 arr.length 大,所以这里做个健壮性判断
// 这一步是构建一个小堆(先把小于等于 k 的元素丢进小堆里面)
for (; index <= Math.min(arr.length, k); index++) {
heap.add(arr[index]);
}
// index 指针接着往后移动
int i = 0;
for (; index < arr.length ; i++, index++) {
heap.add(arr[index]);
// 加一个元素弹一个元素
arr[i] = heap.poll();
}
// 把剩下的元素全部弹出来
while (!heap.isEmpty()) {
arr[i++] = heap.poll();
}
}